本篇還是會再提 Hadoop,以對照 MPP 的特點。
Massive Parallel Processing(MPP) 實際上是一種架構。
理論上依據應用場景,MPP 與 Hadoop 是打不到一起,無奈台灣企業的資料量多半不會很大,所以我經常遇到專案 Greenplum 與 Hadoop 對打的狀況,特性迥異反而很傷腦筋。
| / | 歸屬陣營 | 資料儲存架構 | 最適資料類別 | 適用資料規模 | 最適節點數 | 系統資源調度 |
|---|---|---|---|---|---|---|
| MPP | DataWarehouse | Database | 結構化 | TB | 百 | 先垂直再水平 |
| Hadoop(Hive) | Data Lake | File System | 半結構化 | PB | 千 | 先水平再垂直 |
分散式系統必要面臨如何記憶資料放在哪個節點的問題,MPP 與 Hadoop 的方法非常不同。
MPP 架構是靠 Hash 計算去找到資料所在的物理節點,所以耗費算力。而且 metadata 每個節點都要儲存,越多節點重複的 metadata 資料會暴增,影響效能。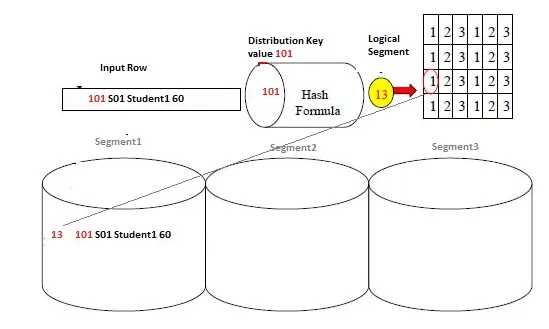
圖片來源:https://dwgeek.com/greenplum-hash-distribution-works.html/
Hadoop 則是靠 namenode 的記憶體去紀錄「檔案」所在的物理節點,所以 Hadoop 需要控制檔案數量,在 namenode 所在節點配置適當大小的記憶體,規劃不當將會影響效能。
這世上沒有一種系統或架構可以適用所有場景
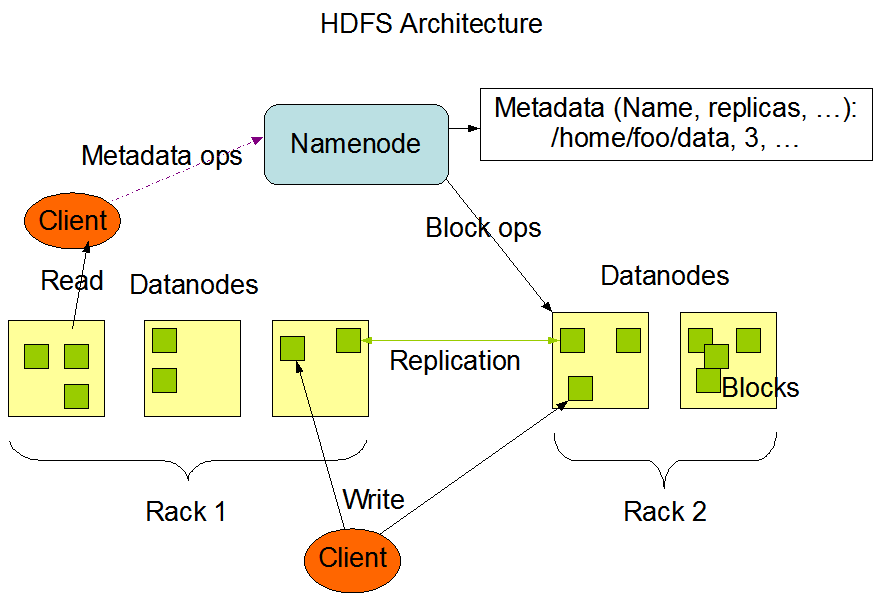
圖片來源:Apache Hadoop
因 Hadoop(Hive) 基於 MapReduce 架構在千萬筆資料以下並無查詢效能優勢,必須在億級資料筆數才能發揮長處。Hadoop 陣營後來不甘示弱,加入 Impala 與 Presto 這些基於 HDFS 的 MPP 架構的元件,以對應 ad-hoc query 需求。
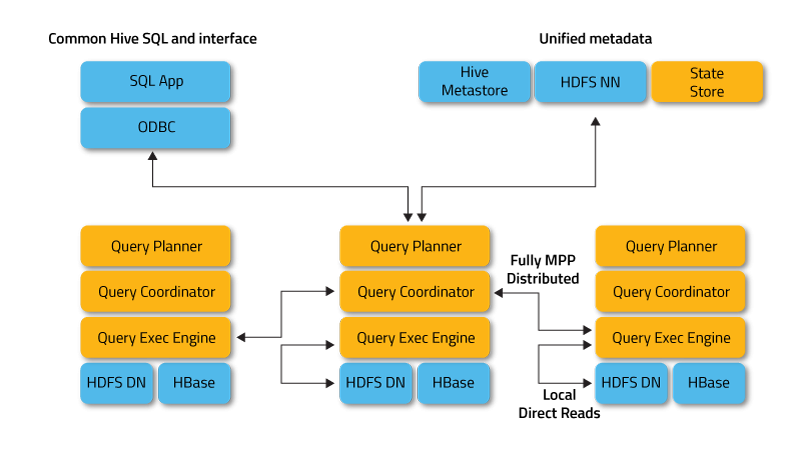
圖片來源:https://impala.apache.org/overview.html
目前這兩個架構逐漸框定自己的主場,好像暫時誰也不會取代誰,都繼續發展中。因此,資訊或是資料領域面對的挑戰是越來越複雜的,我們才講了 8 個詞彙就感覺這些架構與系統五花八門、眼花撩亂,都各自有自己的設計思維與優點。
我常覺得 System Integrator (系統整合商)真正的價值是為客戶選擇產品、組成方案,去對應客戶的商業場景,而不是當原廠的擁護者。
業界還有另一個鄙視鏈,甲方的技術崗位不如乙方的,乙方的系統整合商不如 Distributor (代理商),代理商不如 Vendor (原廠)的技術崗位。何時系統整合商可以改變腦死站隊原廠的現況,回歸技術專業導向,也許就會慢慢改觀。不改也沒關係,開源陣營夾著 AI 狂潮正在席捲而來,屆時連原廠是誰都會是個頭昏腦脹的問題。懂的人看這則新聞就知道我在說什麼了:使用其人工智慧服務發生智慧財產權糾紛時,微軟保證承擔相關法律問題、賠償費用。
一般的 MPP 還有這個 ClickHouse 。
台灣因中小企業居多,一般項多用到 MPP 的資料庫。
如我的經驗永豐銀由sql server 轉 ibm netezza + Cognos.
tkec 指定年份內資料量低於2仟萬筆,olap cube 直接用mysql/progress 連mpp都不用。
另外題外話,mpp的優化也是一門學問。畢竟跟傳統的RMDBS還是有一定差別。
非常贊同。
寶貴實務經驗

